쿠버네티스의 실질적인 실행 주체인 파드(Pod)와 그를 둘러싼 자원 관리 체계에 대해 깊이 있게 다룰 차례다. 파드의 특성을 무시한 설계는 반드시 운영 단계에서 '불꽃놀이(장애)'를 일으킨다는 것이다.
1. 파드(Pod)의 네트워크 및 통신 구조
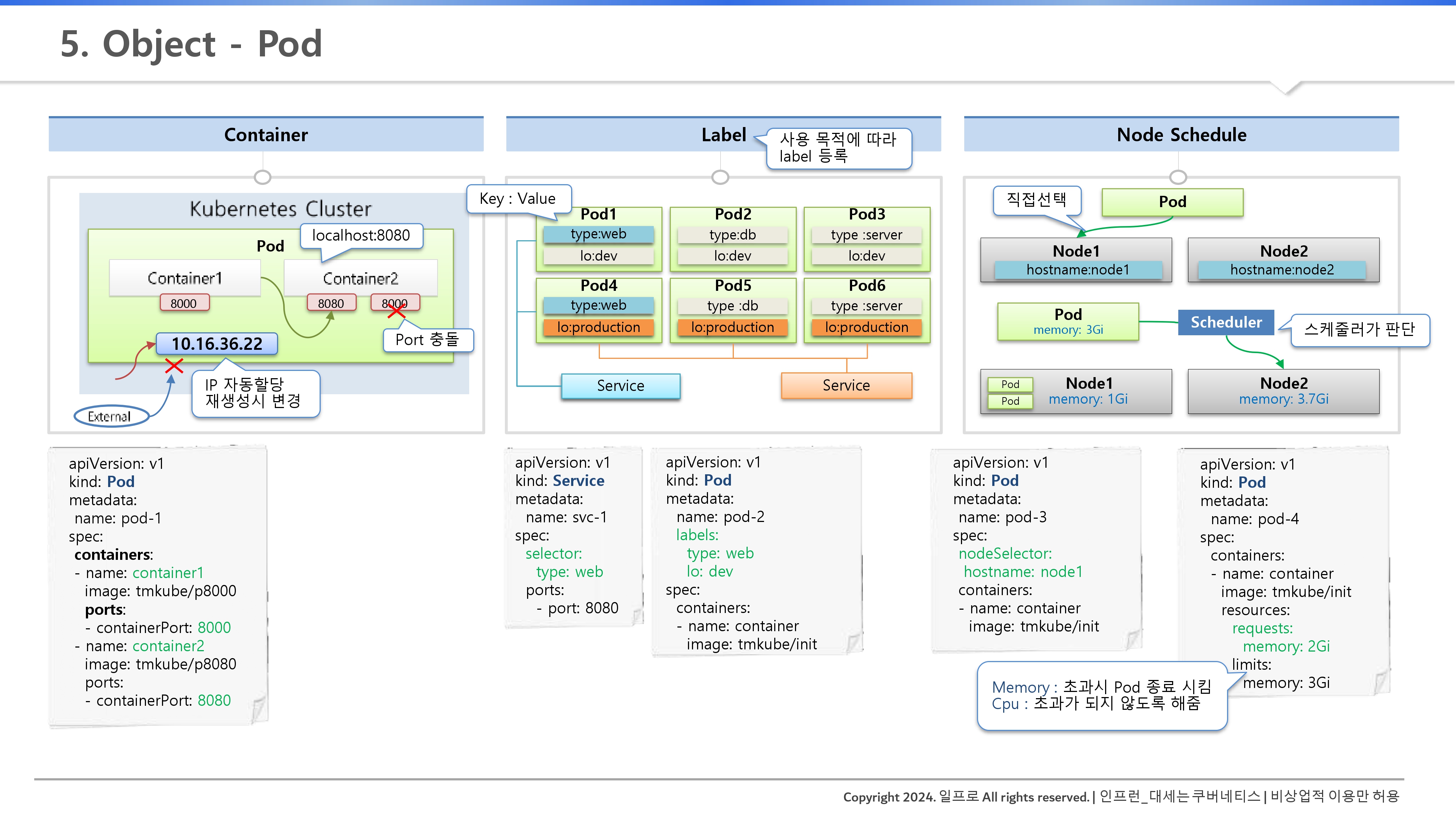
- 공유 네트워크 환경: 한 파드 내의 컨테이너들은 네트워크 네임스페이스를 공유한다. 즉, localhost를 통해 서로 통신할 수 있다. 단, 포트가 중복되면 충돌이 발생한다.
- 휘발성 IP 주소: 모든 파드는 고유 IP(10.16.36.22)를 할당받지만, 파드가 죽고 재생성되면 IP는 반드시 변한다. 따라서 파드 IP를 설정 파일에 직접 박아 넣는 행위는 금기다.
- 내부 접근 전용: 할당된 IP는 쿠버네티스 클러스터 내부에서만 유효하며 외부에서는 직접 접근할 수 없다.
2. 라벨(Label)과 셀렉터(Selector)
- 유연한 분류 체계: 키-밸류(Key-Value) 쌍으로 구성된 해시태그다. type:web, Io:dev
- 연결의 핵심: 서비스(Service)나 컨트롤러는 파드 IP가 아닌 이 라벨을 보고 어떤 파드를 관리할지 결정한다.
3. 스마트한 배치: 노드 스케줄링
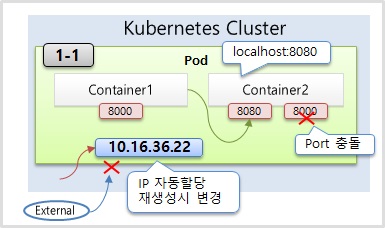
- 수동 지정: nodeSelector를 사용하여 특정 라벨이 붙은 노드(hostname: node1)에 파드를 강제로 배치한다.
- 자동 배치: 쿠버네티스 스케줄러가 노드들의 남은 자원(CPU, Memory)을 계산하여 가장 적합한 곳에 파드를 던져준다.
4. 자원 격리 (Requests & Limits)
- Requests (최소 보장): "나 적어도 이만큼은 필요해"라는 선언이다. 스케줄러는 이 값을 기준으로 노드를 선택한다.
- Limits (최대 한도): "나 아무리 바빠도 이 이상은 안 쓸게"라는 약속이다. 이 설정을 안 하면 파드 하나가 노드 전체 자원을 갉아먹는 '시끄러운 이웃(Noisy Neighbor)' 문제가 발생한다.
💡 꼬리 질문 & 답변
Q: 메모리는 Limit을 넘으면 바로 죽여버리고(OOMKill), CPU는 왜 느려지게(Throttling)만 할까? 이 차이가 운영 환경에서 왜 중요한가?
A: 자원의 '압축성(Compressible)' 유무 차이 때문이다.
- CPU (압축성 자원): CPU는 시간을 쪼개서 나눠 쓸 수 있다. 한 프로세스가 너무 많이 쓰면 OS가 실행 시간을 줄여버리면(Throttling) 된다. 시스템이 느려질 뿐, 프로세스 자체가 깨지지는 않는다.
- Memory (비압축성 자원): 메모리는 물리적 공간이다. 이미 데이터가 차 있는 공간을 억지로 뺏을 방법이 없다. 만약 다른 프로세스의 메모리 영역을 침범하게 두면 시스템 전체가 뻗는다. 따라서 쿠버네티스는 노드 전체를 보호하기 위해 선을 넘은 파드를 즉시 Kill(OOMKill) 하는 극단적인 선택을 하는 것이다.
이 차이를 모르면 "왜 우리 앱은 트래픽이 몰릴 때 재시작이 반복될까?"라는 질문에 답할 수 없다. 메모리 사용량은 항상 Limit 값을 신중하게 설계해야 한다.
이론을 실습으로 바꾸는 가장 중요한 과정이다.
1. 파드(Pod) 내부 통신과 IP의 특성
- 로컬 통신: 한 파드 내의 컨테이너들은 네트워크 공간을 공유하므로 localhost와 포트 번호만으로 서로 통신이 가능하다.
- 포트 충돌: 파드 내 두 컨테이너가 동일한 포트(예: 8000)를 사용하면 충돌이 발생하여 파드가 정상적으로 실행되지 않고 재생성을 반복한다.
- IP의 휘발성: 파드에 할당된 IP는 클러스터 내부용이며, 파드가 삭제 후 재생성되면 IP 주소는 반드시 변경된다.
2. 라벨(Label)과 서비스(Service)의 유연한 연결

- 분류 체계: 라벨은 key:value 형태로 파드에 부여되며, 목적(개발/운영)이나 기능(Web/DB)에 따라 자유롭게 설정할 수 있다.
apiVersion: v1
kind: Service
metadata:
name: svc-for-web
spec:
selector:
type: web
ports:
- port: 8080
---
apiVersion: v1
kind: Service
metadata:
name: svc-for-production
spec:
selector:
lo: production
ports:
- port: 8080- 동적 연결: 서비스의 selector 값을 수정하는 것만으로 특정 라벨을 가진 파드 그룹에 실시간으로 트래픽을 전달할 수 있다. 예를 들어, lo: production 라벨로 변경하면 운영 환경 파드들만 즉시 서비스에 연결된다.
3. 전략적 노드 스케줄링
apiVersion: v1
kind: Pod
metadata:
name: pod-3
spec:
nodeSelector:
kubernetes.io/hostname: k8s-worker1
containers:
- name: container
image: kubetm/init- 수동 지정: nodeSelector를 사용하여 특정 호스트 네임(예: k8s-worker1)을 가진 노드에 파드를 강제로 배치할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: pod-4
spec:
containers:
- name: container
image: kubetm/init
resources:
requests:
memory: 2Gi
limits:
memory: 3Gi- 자동 스케줄링: 리소스 요청량(requests)을 명시하면 쿠버네티스 스케줄러가 노드별 잔여 자원량을 점수화하여 가장 여유 있는 노드에 파드를 할당한다.
- 자원 제한의 결과: 메모리가 설정된 limits를 초과하면 파드는 즉시 종료(OOM)되지만, CPU는 성능이 저하(Throttling)될 뿐 파드가 죽지는 않는다.
💡 꼬리 질문 & 답변
Q: 실습에서 ReplicationController 대신 Deployment를 사용하여 파드를 관리했다. 파드를 직접 생성(kubectl run)하지 않고 이런 컨트롤러를 통해 생성해야만 하는 결정적인 이유는 무엇인가?
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-1
spec:
replicas: 1
selector:
matchLabels:
app: deploy
template:
metadata:
name: pod-1
labels:
app: deploy
spec:
containers:
- name: container
image: kubetm/init
A: 결론부터 말하면, "선언적 데이터베이스와 자가 치유(Self-healing)" 때문이다.
- 직접 생성 시: 파드가 어떤 이유로 삭제되면 그것으로 끝이다. 아무도 다시 살려주지 않는다.
- 컨트롤러 사용 시: 사용자가 "파드 1개를 유지해라"라고 선언(spec.replicas: 1)하면, 컨트롤러는 현재 상태를 감시하다가 파드가 삭제되는 즉시 새로운 파드를 생성하여 선언된 상태를 유지한다.
현업에서는 장애 상황에서도 서비스 중단을 막기 위해 반드시 Deployment와 같은 컨트롤러를 통해 파드를 관리해야 한다.
위 학습용 정리 내용 및 사진 자료는 "인프런_대세는 쿠버네티스(https://inf.run/Lv5RV)" 강의를 소스로 작성하였습니다.
'Cloud Native > Kubernetes' 카테고리의 다른 글
| 3. Volume - emptyDir, hostPath, PV/PVC (0) | 2026.01.16 |
|---|---|
| 2. Service - ClusterIP, NodePort, LoadBalancer (0) | 2026.01.16 |
| 5. 쿠버네티스 클러스터의 논리적 아키텍처와 객체 간 유기적 관계망의 이해 (0) | 2026.01.15 |
| 4. 네이티브 환경에서 컨테이너를 거쳐 쿠버네티스 객체로 진화하는 단계별 배포 아키텍처 실습 시나리오 (1) | 2026.01.15 |
| 3. 커널 공유 기반의 격리 기술과 마이크로서비스 아키텍처(MSA)를 위한 컨테이너 활용 전략 (0) | 2026.01.15 |