개발보다 어려운 게 '무중단 배포'다. 서비스가 중단되는 순간 고객은 떠나고, 그 책임은 우리가 진다. 이번에는 서비스를 어떻게 안전하게 업그레이드할 것인지, 그 전략과 디플로이먼트(Deployment)의 실체에 대해 알아보자.
Deployment는 현재 한 서비스가 운영 중인데, 이 서비스를 업데이트 해야해서 재배포를 해야될 때 도움을 준다.
1. 서비스 업그레이드 전략: 상황에 맞는 선택
인프라를 어떻게 갈아끼울 것인가는 자원 상황과 서비스 중요도에 따라 결정된다.
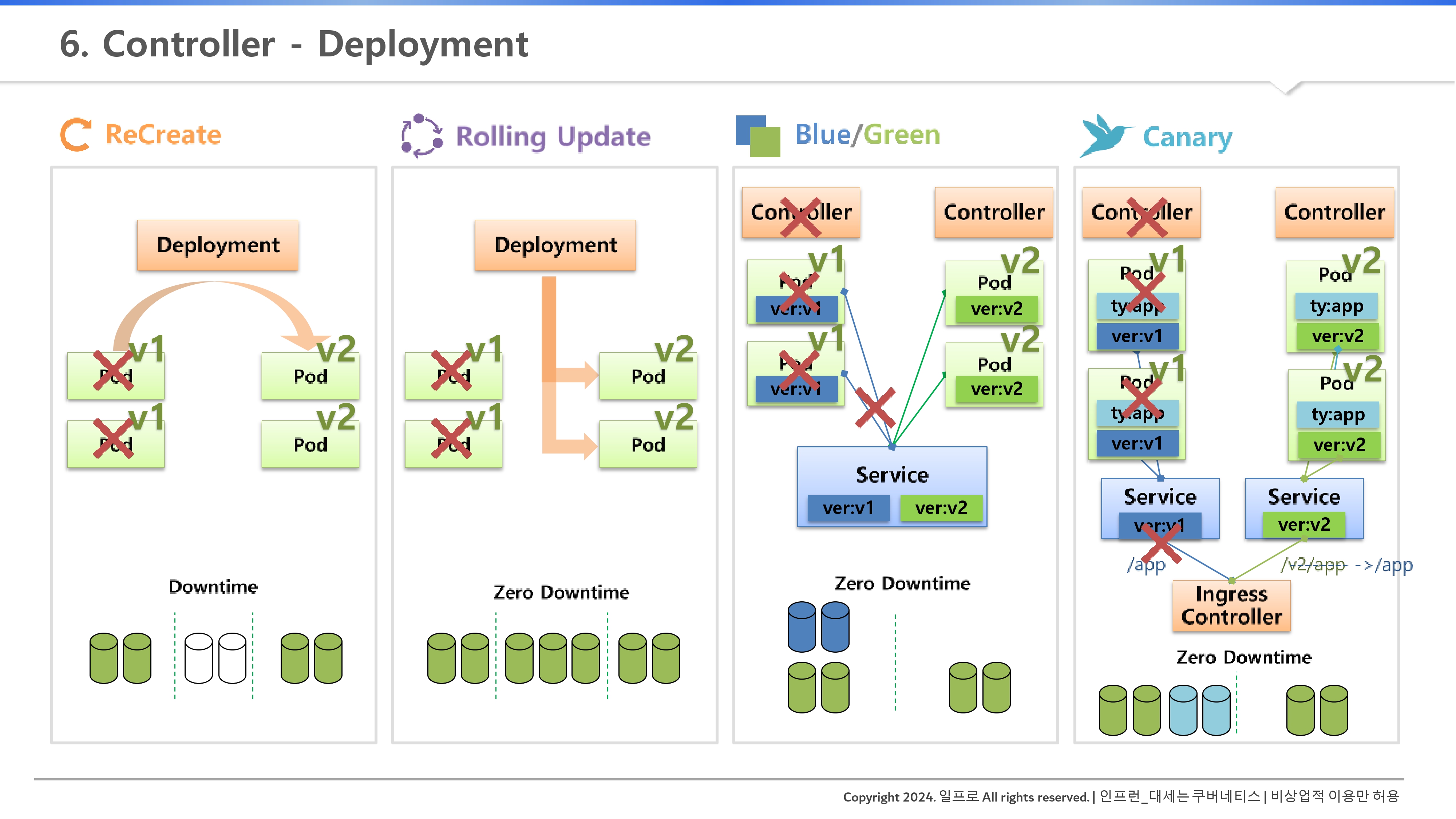
- Recreate (재생성): 기존 파드를 모두 죽이고 새 버전을 띄운다. 자원 사용량은 적지만 다운타임(Downtime)이 반드시 발생한다. 일시 정지가 허용되는 서비스에만 쓴다.
- 파드 삭제 → 다운타임 → 자원 사용량 없어짐.
- Rolling Update (롤링 업데이트): 파드를 하나씩 순차적으로 교체한다. 무중단 배포가 가능하며 쿠버네티스의 기본값이다. 배포 도중 추가 자원이 필요하다는 점을 명심하자.
- 먼저 v2의 파드 1개 생성 → v1, v2 모두 서비스 운영 중 (랜덤 접속될 것)
- → v1 파드 1개 삭제 → v2 파드 1개 더 생성 → v1 파드 남은 1개 삭제.
- 즉, 위 과정에서 v2의 파드 1개 생성할 때 배포 도중 추가 자원이 필요해지게되는 것.
"서비스가 라벨을 보고 Pod를 찾는구나"
- Blue/Green (블루/그린): 구버전(Blue)과 신버전(Green) 환경을 통째로 띄워놓고 서비스 셀렉터만 한 번에 바꾼다. 다운타임이 거의 없고 롤백이 매우 빠르지만, 자원이 2배로 든다.
- Deployment 자체 제공 기능은 아니다. ReplicaSet과 같이 모든 컨트롤러를 이용해서 할 수 있음.
- 컨트롤러를 통해 파드가 생성 → 파드에는 라벨 존재 → 서비스의 Selector와 연결
- → 이 상태에서 컨트롤러를 하나 더 만든다(v2에 대한). → 이로써 기존 자원 사용량의 2배가 되는 것
- → 이러면 준비가 완료된건데, 이때 서비스의 라벨을 완전히 v2로 교체해서 기존 파드(v1)과 관계를 끊어버려 변경이 된다. → 그래서 순간적으로 변경되기 때문에 다운타임이 거의 없는 것이다.
- 롤백을 원할 때는 v1으로 간단하게 교체만 하면 되기 때문에 또 대중적이다.
- Canary (카나리): 소수의 유입 트래픽에만 신버전을 노출(=실험체로 위험 검증)해 검증한 뒤 전체로 확대한다. 광산의 카나리아처럼 위험을 미리 감지하는 방식이다. 인그레스(Ingress) 등을 활용해 정교한 트래픽 제어가 가능하다. 다운타임이 거의 없고, 자원은 v2에 대한 파드(테스트용을 얼마나?)를 얼마나 만들 것이냐에 따라 증가한다.

- v1이 아닌 type:app으로 라벨을 만들어 서비스를 연결하는 것이다.
- 이 상태에서 테스트 용으로 컨트롤러를 만든다. → ReplicaSet을 1로 설정하여 v2의 파드를 하나 만든다. → 똑같이 type:app이라고 라벨을 단다. → 자동으로 아까 서비스에 연결이 된다.
- → 그러면 연결이 되어있으니 트래픽 중 일부가 v2로 접근이 될 것이고 자연스럽게 테스트가 진행된다. → 그러다 문제가 발생하면 ReplicaSet을 0으로 만들면 간단하다.

- v1은 v1대로, v2는 v2대로 각각의 서비스를 만든다.
- → IngressController라는 컨트롤러가 유입되는 트래픽을 URL Path(/app, /v2/app)에 따라서 연결을 해주는 역할을 한다.
- → Path 앞에 v2 (EN 등 다양함)가 있으면 새 버전에 대한 서비스가 사용되게 된다(이렇게 특정 타겟을 정해두고 테스트를 진행하는 것이다).
- → 테스트 기간이 종료되는 v2의 파드를 1개에서 2개 등으로 증가시킨다.
- → 기존 v1에 대한 내용과 파드를 삭제한다. → IngressController 설정을 그냥 /app으로 변경해주면 끝이다(자연스래 옮겨짐).
2. Deployment의 내부 동작 원리
Deployment는 파드를 직접 관리하지 않는다. 이 녀석은 리플리카셋(ReplicaSet)을 부리는 '관리자'일 뿐이다.
- 리플리카셋 조종: 배포 시 디플로이먼트는 새로운 리플리카셋을 생성하고, 이전 리플리카셋의 복제본 수를 조정하며 파드를 교체한다.
- 그리고, Deployment를 만들 때, Replica에서 넣었던 selector, replicas, template을 동일하게 넣는 것이다. (ReplicaSet을 만들고 값을 지정해주기 위한 용도임)
- 그래서 파드들이 ReplicaSet을 기반으로 만들어진다. → 서비스를 만들고 Pod들과 연결된다.
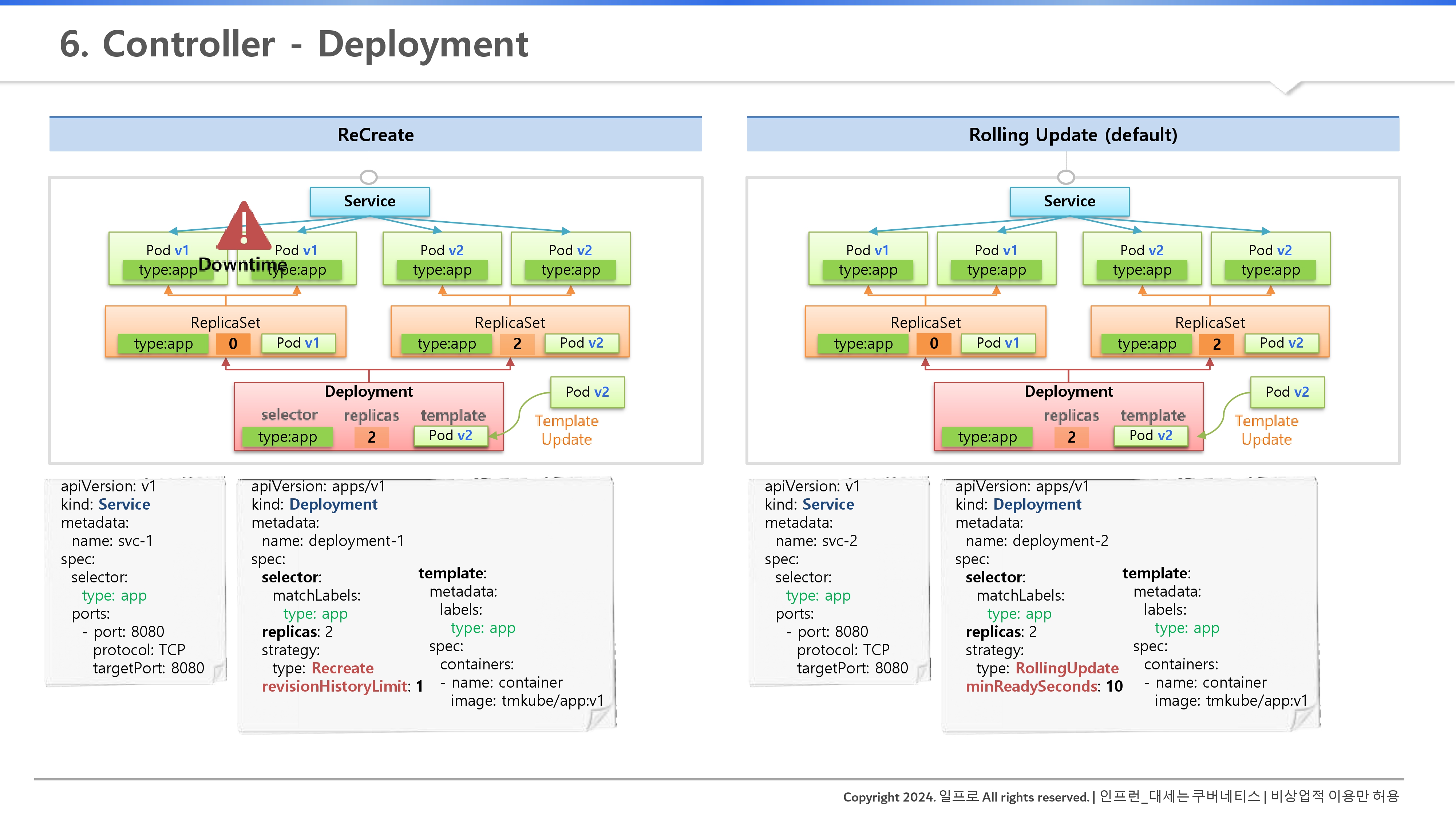
- Recreate 방식의 내부
- 이전 리플리카셋의 replicas를 0으로 만든다.
- 다운타임이 생긴다.
- 새 리플리카셋을 원하는 수만큼 올린다.
- 이력 관리 (Revision History): Optional인 revisionHistoryLimit 설정을 통해 구버전 리플리카셋을 남겨둘 수 있다. 기본값은 10개이며, 이를 이용해 언제든 안정적인 이전 버전으로 롤백할 수 있다.
- Rolling Update 방식의 내부
- 새 리플리카셋을 하나씩 늘린다(Scale Up).
- 즉, 새 리플리카셋의 replicas(오른쪽)를 처음에는 '1'로 설정하는 것이다.
- 이 동안은 다운타임도 없고, v1 2개와 v2 1개가 서비스에 연결돼서 트래픽이 세 곳으로 분산될 것이다.
- 기존 리플리카셋을 하나씩 줄이며(Scale Down) 점진적으로 교체한다.
- 기존 리플리카셋의 replicas(왼쪽)를 '2'에서 '1'로 줄인다 = 삭제된다.
- 새 리플리카셋의 replicas(오른쪽)를 '1'에서 '2'로 늘린다.
- 기존 리플리카셋의 replicas(왼쪽)를 '1'에서 '0'로 줄인다 = 완전 삭제된다.
- 새 리플리카셋을 하나씩 늘린다(Scale Up).
- 이력 관리 (Revision History): revisionHistoryLimit 설정을 통해 구버전 리플리카셋을 남겨둘 수 있다. 기본값은 10개이며, 이를 이용해 언제든 안정적인 이전 버전으로 롤백할 수 있다.
- 고유 라벨 매칭: 롤링 업데이트 중 서로 다른 리플리카셋의 파드가 섞이지 않도록, 쿠버네티스는 내부적으로 고유한 해시 라벨을 생성해 관계를 정확히 유지한다.
- 잘 생각해보면 라벨이 다 같은데, 새로운 ReplicaSet이 기존 ReplicaSet의 파드와 연결 안된다는 보장은 없으니, 추가적인 해시 라벨과 Selector를 더 만들어줘야하는 것인데, 실습에서 확인하자.
💡꼬리 질문
Q: 롤링 업데이트 시 서비스가 중단되지 않는 핵심 조건 중 하나는 '새로 뜬 파드가 실제로 요청을 받을 준비가 되었는가'를 판단하는 것이다. 이를 위해 디플로이먼트 스펙에서 반드시 함께 고려해야 할 기능은 무엇일까?
결론: Readiness Probe(준비성 프로브)와 minReadySeconds 설정을 함께 사용해야 한다.
- Readiness Probe: 쿠버네티스가 단순히 파드가 '실행 중(Running)'인 것을 넘어, 애플리케이션 초기화가 끝나고 실제 트래픽을 처리할 수 있는지 검사.
- 안전 장치: 이 프로브가 통과되어야만 해당 파드를 서비스 엔드포인트에 추가하고, 기존 파드를 삭제하기 시작.
- 지연 시간 부여: 강의에서 언급된 minReadySeconds는 파드가 준비된 후 다음 파드 교체로 넘어가기 전의 최소 대기 시간을 보장하여, 배포 과정의 안정성을 시각적으로 확인하거나 모니터링할 시간을 벌어준다.
배포(Deployment) 전략을 선택하는 기준은 딱 하나다. "우리 서비스가 1초의 중단도 허용하는가?" 중단이 허용되지 않는다면 롤링 업데이트나 블루/그린을, 자원이 부족하고 일시 정지가 가능하다면 Recreate를 선택하자.
1. Recreate (재생성): 확실하지만 아픈 방식

- 동작 원리: 기존 리플리카셋의 복제본을 0으로 만든 뒤, 새 리플리카셋을 생성한다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-1
spec:
selector:
matchLabels:
type: app
replicas: 2
strategy:
type: Recreate
revisionHistoryLimit: 1
template:
metadata:
labels:
type: app
spec:
containers:
- name: container
image: kubetm/app:v1
terminationGracePeriodSeconds: 10
apiVersion: v1
kind: Service
metadata:
name: svc-1
spec:
selector:
type: app
ports:
- port: 8080
protocol: TCP
targetPort: 8080
- 특징: app:v2로 업데이트(=수정) 하는 순간 어떻게 될까? 바로, 배포 순간에 파드를 다운시켜 다운타임(Downtime)이 발생하여 서비스가 끊긴다. v2로 재배포 될때까지 말이다. 대신 추가 자원이 동시에 소모되지 않는다는 장점이 있다.
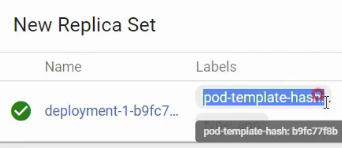
- 핵심 필드: pod-template-hash. 디플로이먼트는 이 고유 라벨을 통해 여러 리플리카셋 사이에서 자신의 파드를 정확히 식별한다.
- 이력 관리: revisionHistoryLimit: 1로 설정하면 이전 리플리카셋을 딱 하나만 남기고 나머지는 삭제하여 클러스터를 깨끗하게 유지한다.
# Kubectl 명령으로 Rollback
kubectl rollout undo deployment deployment-1 --to-revision=1
kubectl rollout history deployment deployment-1
2. RollingUpdate (롤링 업데이트): 쿠버네티스의 표준

apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-2
spec:
selector:
matchLabels:
type: app2
replicas: 2
strategy:
type: RollingUpdate
minReadySeconds: 10
template:
metadata:
labels:
type: app2
spec:
containers:
- name: container
image: kubetm/app:v1
terminationGracePeriodSeconds: 0
위 같이 type을 RollingUpdate로 지정 후 생성하면, Deployment와 replicas: 2 만큼의 Pod 2개가 자동으로 생성되고, ReplicaSet 또한 자동으로 생성된다. 서비스는 아래와 같이 붙인다.
apiVersion: v1
kind: Service
metadata:
name: svc-2
spec:
selector:
type: app2
ports:
- port: 8080
protocol: TCP
targetPort: 8080
- 동작 원리: 파드를 하나씩 순차적으로 교체한다. 배포 중 V1과 V2 버전의 파드가 섞여서 서비스되는 구간이 존재한다.
- Deployment에서 app:v1에서 app:v2로 바꾸면, 자동으로 v2 파드가 생성이되고, 섞여서 트래픽이 분산되다가
- 점차적으로 v1이 삭제되다가 모두 v2로 바뀌게 되는 것이다.
- 특징: 다운타임이 전혀 없다. 하지만 배포 중에 V1과 V2 파드가 공존하므로 일시적으로 더 많은 CPU/메모리 자원이 필요하다.
3. 필수 운영 명령어
- 이미지 업데이트: kubectl set image deployment <이름> <컨테이너>=<이미지>
- 이력 확인: kubectl rollout history deployment <이름>
- 롤백 실행: kubectl rollout undo deployment <이름> --to-revision=<번호>
4. Blue/Green (블루/그린): 안정적인 즉시 전환
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: replica1
spec:
replicas: 2
selector:
matchLabels:
ver: v1
template:
metadata:
labels:
ver: v1
spec:
containers:
- name: container
image: kubetm/app:v1
terminationGracePeriodSeconds: 0
apiVersion: v1
kind: Service
metadata:
name: svc-3
spec:
selector:
ver: v1
ports:
- port: 8080
protocol: TCP
targetPort: 8080
수정
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: replica2
spec:
replicas: 2
selector:
matchLabels:
ver: v2
template:
metadata:
labels:
ver: v2
spec:
containers:
- name: container
image: kubetm/app:v2
terminationGracePeriodSeconds: 0
apiVersion: v1
kind: Service
metadata:
name: svc-3
spec:
selector:
ver: v2
ports:
- port: 8080
protocol: TCP
targetPort: 8080
- 동작 원리: 디플로이먼트 자체 기능이라기보다 서비스의 Selector를 변경하여 트래픽을 한 번에 전환하는 방식이다.
- 특징: V2 환경을 완벽히 구축한 뒤 서비스 라벨만 ver: v1에서 ver: v2로 바꾸면 즉시 모든 트래픽이 이동한다. 장애 발생 시 셀렉터를 다시 원복하는 것만으로 초고속 롤백이 가능하다.
💡꼬리 질문
Q: 롤링 업데이트 중 새로운 버전(V2)의 파드에 심각한 버그가 있어 앱이 실행 직후 계속 크래시(Crash)가 난다면, 디플로이먼트는 배포를 어떻게 처리하며 기존 서비스(V1)는 안전할까?
결론: 기존 파드(V1)는 보존되며 배포는 중단된다.
- 배포 중단: 쿠버네티스는 새 파드가 정상 상태(Ready)가 되지 않으면 다음 파드 교체로 넘어가지 않는다. V2 파드가 계속 실패하면 배포 프로세스는 그 지점에서 멈춘다.
- 서비스 보호: 아직 삭제되지 않은 V1 파드들이 남아 있어 트래픽을 처리하므로, 전체 서비스가 완전히 죽는 최악의 상황은 면할 수 있다.
- 실무 대응: 이때 엔지니어는 kubectl rollout status로 배포 정지를 확인하고, kubectl rollout undo를 실행해 배포를 취소하여 클러스터를 안정적인 이전 상태로 되돌려야 한다.
위 학습용 정리 내용 및 사진 자료는 "인프런_대세는 쿠버네티스(https://inf.run/Lv5RV)" 강의를 소스로 작성하였습니다.
'Cloud Native > Kubernetes' 카테고리의 다른 글
| 1. Pod - Lifecycle (0) | 2026.01.24 |
|---|---|
| 8. DaemonSet, Job, CronJob (1) | 2026.01.24 |
| 6. ReplicaSet - Template, Replicas, Selector (0) | 2026.01.22 |
| 5. Namespace, ResourceQuota, LimitRange (0) | 2026.01.18 |
| 4. ConfigMap, Secret - Env, Mount (0) | 2026.01.18 |