서비스를 잘 만드는 것만큼 중요한 게 바로 "운영 중인 서비스가 지금 어떤 상태인지"를 정확히 파악하는 것이다.
쿠버네티스 아키텍처에서 로깅(Logging)은 앱의 입에서 나오는 '말(로그 데이터)'을 관리하는 것이고,
모니터링(Monitoring)은 '건강 상태(CPU/메모리 자원)'를 체크하는 것이라 보면 된다.
1. 쿠버네티스 로깅/모니터링 아키텍처 개요
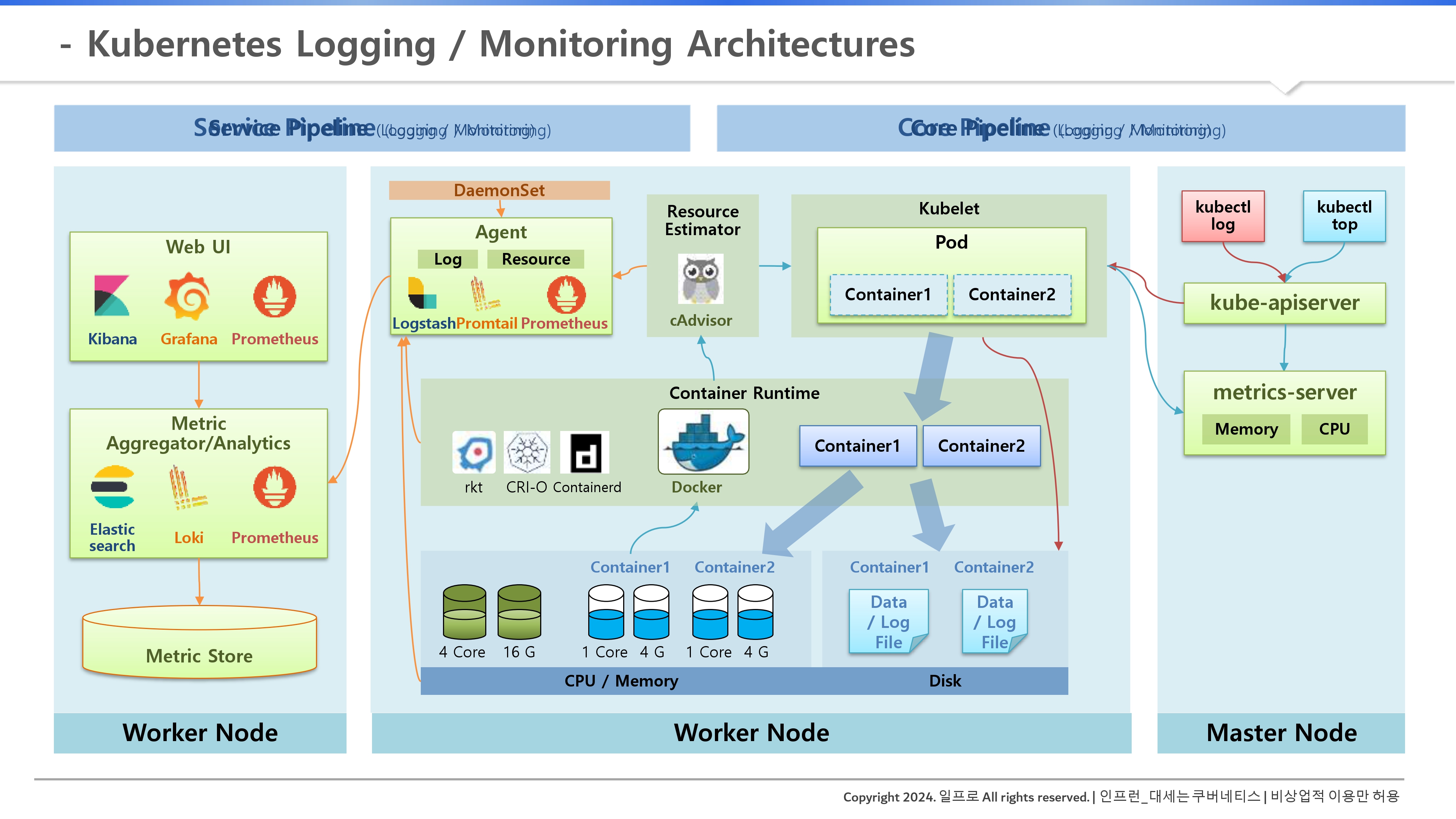
쿠버네티스는 기본적으로 제공하는 코어 파이프라인과 기능을 확장할 수 있는 서비스 파이프라인으로 나뉜다.
1. 코어 파이프라인 (Core Pipeline)
- 자원 관리: 각 노드의 큐블렛(Kubelet)은 C-Advisor를 통해 CPU/메모리 정보를 수집하고, 이를 매트릭 서버(Metrics Server)로 모은다. 사용자는 kubectl top 명령으로 이를 조회한다.
- kubectl top pod을 쳤는데 error: Metrics API not available이 뜬다면, 매트릭 서버가 안깔려있는 것이다.
- 로그 조회: kubectl logs 명령을 치면 API 서버를 거쳐 큐블렛이 해당 컨테이너의 로그 파일을 직접 보여준다.
kubectl top 명령어의 동작 원리 (Core Pipeline)
이 명령어는 쿠버네티스의 코어 파이프라인(Core Pipeline) 아키텍처를 기반으로 움직인다. 데이터가 나의 터미널에 찍히기까지의 여정은 다음과 같다.
1. C-Advisor (데이터 생성): 각 워커 노드의 큐블렛(Kubelet) 안에 있는 리소스 예측기인 C-Advisor가 컨테이너의 CPU와 메모리 사용량을 실시간으로 측정한다.
2. Metrics Server (데이터 수집): 클러스터에 별도로 설치된 매트릭 서버(Metrics Server)가 각 노드의 큐블렛으로부터 이 정보들을 주기적으로 수집하여 저장한다.
3. API 서버 (데이터 중계): 사용자가 kubectl top을 치면, 요청은 kube-apiserver로 전달되고 API 서버는 매트릭 서버에 등록된 정보를 조회한다.
4. 출력: 최종적으로 API 서버가 보내준 정보를 바탕으로 노드나 파드의 리소스 상태가 화면에 표시된다.
top
kubelet의 C-Advisor가 측정한 수치(CPU/Memory 사용량)를 매트릭 서버가 모아두면, API 서버가 거기서 데이터를 긁어와서 보여준다. 주요 목적은 "오토스케일링 판단, 부하 감시".
logs
API 서버가 큐블렛에 요청하면, 큐블렛이 노드의 /var/log/pods/ 아래에 쌓인 실제 텍스트 파일(로그 데이터: stdout, stderr)을 읽어서 그대로 보여준다. 주요 목적은 "에러 디버깅, 앱 동작 확인"
2. 서비스 파이프라인 (Service Pipeline)
별도의 플러그인을 설치하는 것이다.
- 에이전트(Agent): 데몬셋(DaemonSet) 형태로 모든 노드에 설치되어 로그와 리소스를 수집한다.
- 서버(Server): 수집된 방대한 데이터를 저장하고 분석한다. 별도의 외부 저장소 구성을 권장한다.
- 웹 UI: 수집 서버에 쿼리를 날려 시각화된 정보를 사용자에게 제공한다. (예: Grafana, Kibana)
2. 노드 레벨 로깅 vs 클러스터 레벨 로깅
로그를 어디까지 보관하고 어떻게 수집하느냐에 따라 전략이 달라진다.
1. 노드 레벨 로깅 (Node-level Logging)

- 구조: 컨테이너 로그는 stdout/stderr로 출력되어야 도커 로깅 드라이버가 이를 파일로 저장할 수 있다. 도커(Docker) 같은 컨테이너 런타임은 컨테이너가 표준 출력(stdout)이나 표준 에러(stderr)로 뱉는 내용만 가로채서 파일로 저장한다.
- 즉, 애플리케이션이 로그를 컨테이너 내부의 특정 파일(예: /app/logs/my.log)에만 쌓고 있다면, /var/log/pods/에는 아무것도 남지 않는다는 것이다. 쿠버네티스 기본 기능으로는 조회가 안 된다.
- 명령어: kubectl exec -it <파드명> -- cat /app/logs/error.log
- 엔지니어의 역할: 그래서 앱을 만들 때 로그를 파일이 아닌 콘솔 출력으로 내보내도록 설정하는 것이 쿠버네티스 환경의 표준이다.
- 즉, 애플리케이션이 로그를 컨테이너 내부의 특정 파일(예: /app/logs/my.log)에만 쌓고 있다면, /var/log/pods/에는 아무것도 남지 않는다는 것이다. 쿠버네티스 기본 기능으로는 조회가 안 된다.
- 그래서 어떻게하나? 경로: /var/lib/docker/containers/ 아래 JSON 형태로 저장되며, 쿠버네티스가 /var/log/pods/ 및 /var/log/containers/에 링크를 걸어 관리한다.
- 즉, /var/log/pods는 '파드 안'에서 관리되는 게 아니라, 파드가 살고 있는 '워커 노드(호스트)' 레벨에서 관리되는 경로다.
- 로그 저장 경로 (/var/log/pods): 가끔 kubectl logs가 안 먹힐 때 직접 노드에 들어가서 로그를 찾을 수 있다.
- 한계: 워커 노드 레벨에서 관리가 되어도, 파드가 삭제되면 컨테이너와 함께 로그 파일도 삭제되어 더 이상 볼 수 없다. 즉, 파드가 살아있는 동안만 유지된다.
- 팁: /dev/termination-log를 활용하면 파드가 죽기 직전의 에러 로그를 kubectl describe 명령으로 쉽게 확인할 수 있다.
2. 클러스터 레벨 로깅 (Cluster-level Logging)
쿠버네티스에서 파드(Pod)가 삭제된 후에도 로그를 확인하기 위해 필요한 로깅 방식이다.
파드가 사라져도 로그를 남기기 위해 외부 수집 서버를 이용하는 방식이다.
- Node Logging Agent: 데몬셋 에이전트가 노드의 로그 파일을 읽어 수집 서버로 전송한다.
- Sidecar Container Streaming: 별도의 사이드카 컨테이너가 특정 로그 파일을 읽어 stdout으로 쏴줌으로써 로그 스트림을 분리한다.
- "메인 컨테이너는 로그를 파일에 쌓고 있고, 이를 외부에서 볼 수 있게 사이드카 컨테이너를 붙여서 stdout으로 쏴줘라"
- '별도의 컨테이너를 만들어 로그를 읽는 구조'인 것이다.
- 그래서 파드명을 딴 .log 파일으로 생성이되는 것이다.
- 즉, 우리는 kubectl logs <파드명> -c <사이드카컨테이너명>으로 로그를 볼 수 있게 된다.
- Sidecar Logging Agent: 파드 안에 에이전트를 직접 넣어 로그를 수집 서버로 바로 쏘는 구조다.
3. 대세는 PLG 스택: 상세 동작 원리
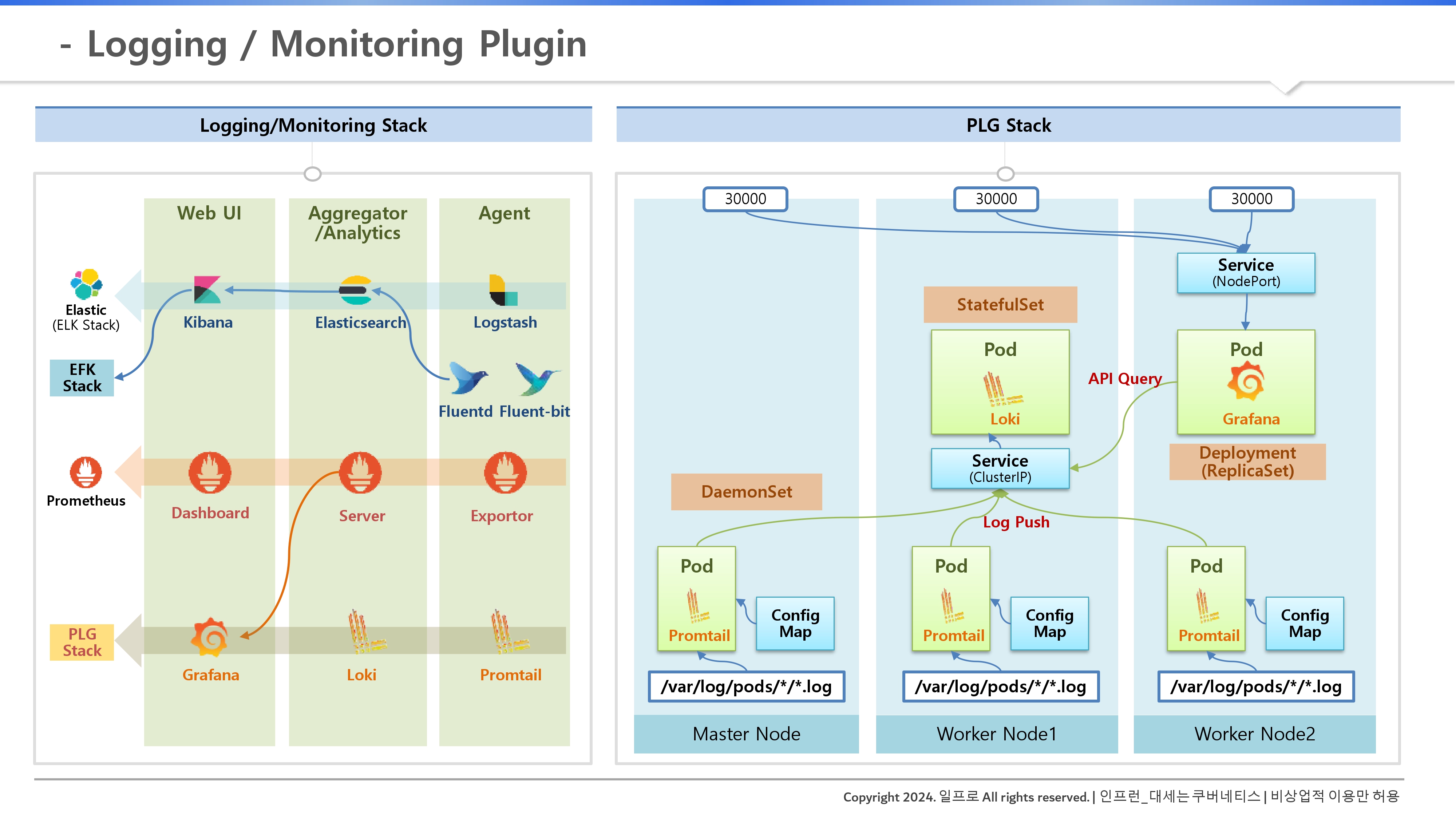
오픈소스 생태계에는 ELK(Elasticsearch, Logstash, Kibana)나 EFK(Fluent Bit) 등 다양한 조합이 있지만, 최근에는 가벼운 PLG 스택이 주목받고 있다.
PLG 스택의 구성 요소
- Promtail (에이전트): 데몬셋으로 모든 노드에 설치되어 로그 패스를 읽고 Loki로 푸시한다.
- Loki (수집 서버): 스테이트풀셋(StatefulSet)으로 설치되어 로그 데이터를 저장하고 쿼리 요청을 처리한다.
- Grafana (웹 UI): 디플로이먼트로 설치되어 Loki에 API 쿼리를 날려 로그를 시각화한다.
💡실무 팁
- 로그를 쌓을 때 가장 흔한 실수가 앱 내부 파일로만 로그를 남기는 것이다.
- 쿠버네티스의 로깅 시스템을 타려면 반드시 스탠다드아웃(stdout)으로 로그를 뱉도록 앱을 설계해라.
- 그래야 나중에 PLG 스택을 붙이든 EFK를 붙이든 고생을 안 한다.
- 그래야 나중에 PLG 스택을 붙이든 EFK를 붙이든 고생을 안 한다.
위 학습용 정리 내용 및 사진 자료는 "인프런_대세는 쿠버네티스(https://inf.run/Lv5RV)" 강의를 소스로 작성하였습니다
'Cloud Native > Kubernetes' 카테고리의 다른 글
| 8. [Architecture]: Storage - File / Object / Block Storage (0) | 2026.01.31 |
|---|---|
| 7-2. [Architecture]: Networking - Service Network (0) | 2026.01.31 |
| 7-1. [Architecture]: Networking - Pod, Pause Container (0) | 2026.01.31 |
| 7. [Architecture]: Networking (0) | 2026.01.31 |
| 6. [Architecture]: Component - kube-apiserver, etcd, kube-schedule, kube-proxy, kube-controlelr-manager (0) | 2026.01.31 |